

In this thread we step through an example Iris session in which the Spectral Energy Distribution (SED) of the FSRQ (flat-spectrum radio quasar) blazar BZQ J2129-1538 is analyzed, to represent the typical path one would take through the tool in order to build, analyze, and save a SED to file. We string together the components of the [Iris How-to Guide][guide] in order to integrate the individual features and capabilities of Iris into one, big picture.
Last Update: 22 Feb 2017 - Updated for Iris 3.0.
In order to visualize an SED of an astronomical object across a wide range of wavelengths, multiple SED segments from various locations must be gathered and co-plotted; Iris features multiple entry points for SED data to facilitate this process. You can load data files from your local disk into Iris, or import SED data directly from the photometry archives of the NASA Extragalactic Database (NED). Independent of how each data set is loaded and from where, Iris can simultaneously plot multiple SED segments together in the main display.
In this thread, we will import two SED segments of BZQJ2129-1538 for analysis in Iris: one from the NED SED archives, and the other from file on disk.
Let us start by launching Iris from the command line:
% /bin/bash # do this for C-shell users ONLY $ source activate iris $ iris
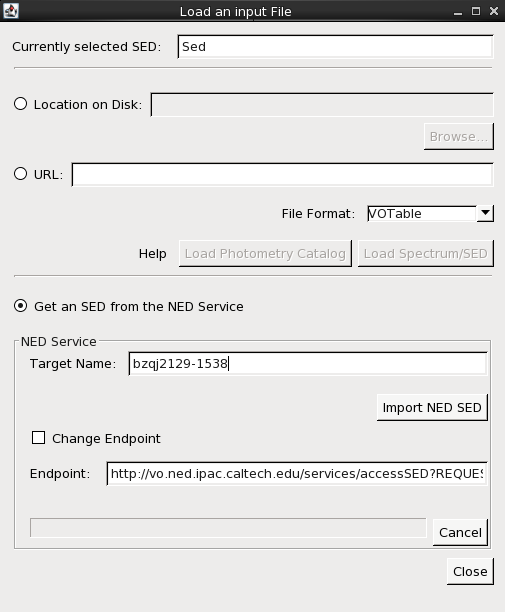
We can choose to import SED data directly from NED via either the Get an SED from the NED Service option in the Iris Load File or Load NED SED icon on the Iris desktop. This feature allows you to search the NED photometry database by object name to return the available SED data for that object.
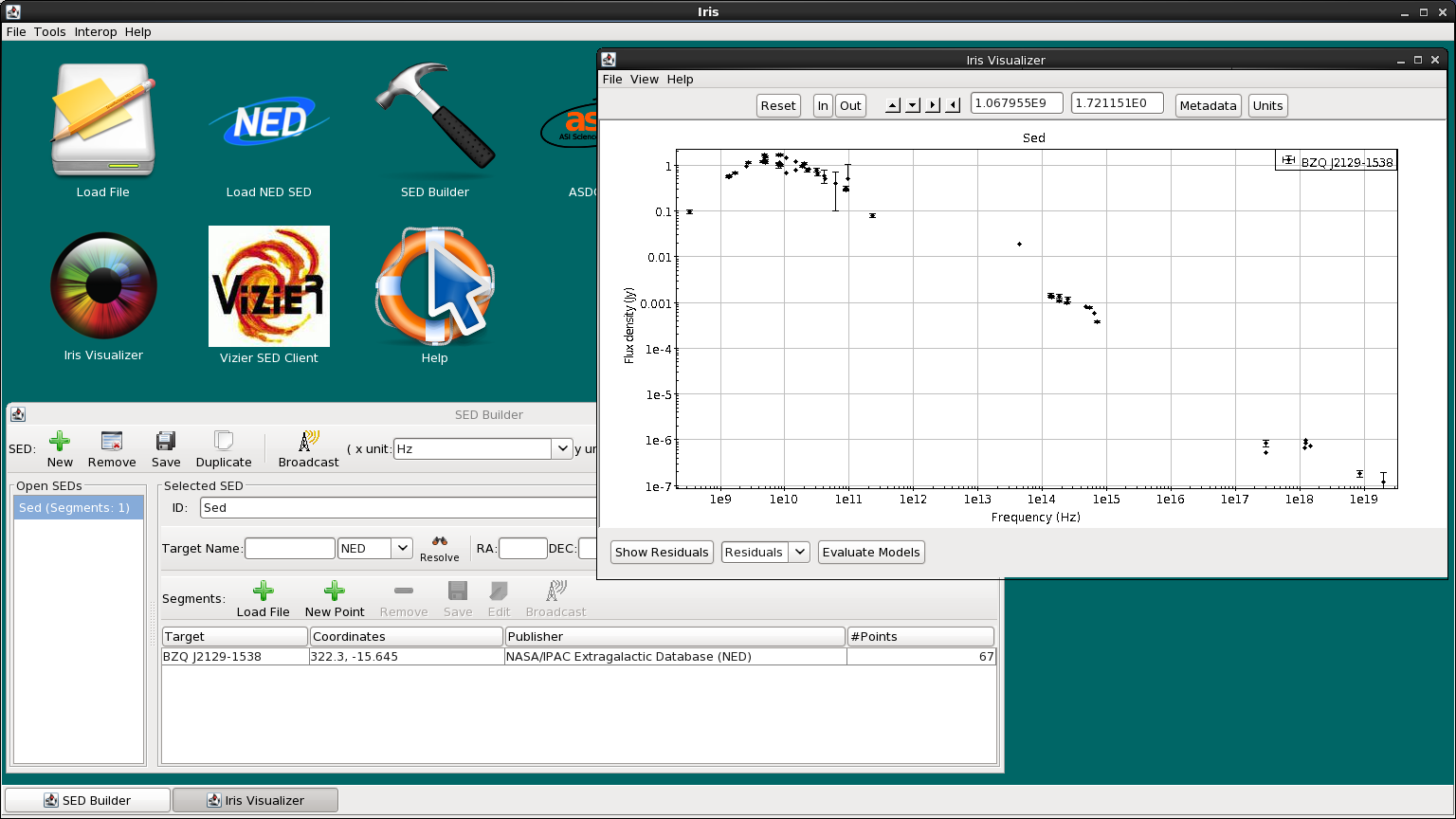
So let’s go ahead and import the BZQJ2129-1538 SED directly from NED. We enter the identifier “bzqj2129-1538” in the Target Name field, and then click Import NED SED to automatically display the SED available for this object in the Iris Visualizer.
| [Back to top] |
An SED data file for an object of interest can be loaded into Iris simply by starting the application and selecting the Load File icon on the Iris dekstop. If the file comes in a format which is not natively supported by Iris - i.e. a file that is not IVOA-compliant FITS or VOTable - then it must first be converted to a supported format in the SED Builder interface before it can be displayed in the Iris Visualizer. You can learn more about the file formats recognized by the SED Builder on the Iris [Supported File Formats][importer_files] page, and refer to the Building and Managing SEDs section of the Iris How-to Guide to learn how to use the SED Builder to convert data for display in Iris.
Looking at the NED SED of BZQ J2129-1538, we notice a large gap of data points in the infrared regime (from around 10^11 to 10^14 Hz). We will fill in a part of this gap using WISE data of this object in ASCII format on file. Download WISE.bzqj2129-1538.dat to get the photometric data. The first column of the file contains the wavelength in Angstroms, and the second and third contain the flux density and corresponding error values, respectively, in ergs/s/cm2/Angstrom.
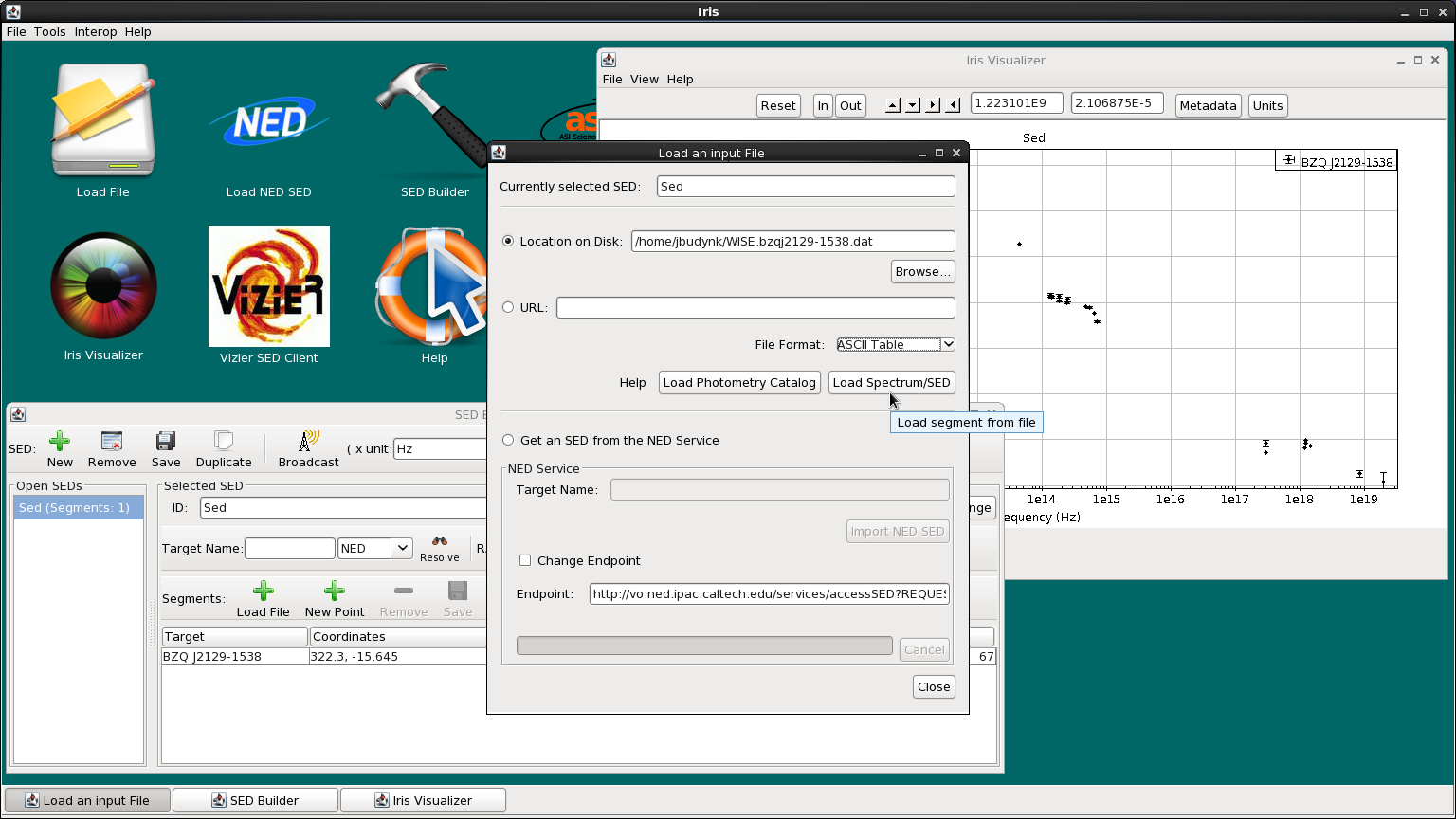
Let’s add the WISE data onto our NED SED of BZQ J2129-1538. Under the “Segments” section in the SED Builder window, click the green plus-sign that says “Load File”. At the top of the “Load an input File” window, we click “Location on Disk”, browse for WISE.bzqj2129-1538.dat, select “ASCII Table” from the menu of file format options, and then click “Load Spectrum/SED”.
| [Back to top] |
Since we would like to analyze a photometric data segment which we have stored in a format not natively supported by Iris, we must configure the file in the Iris SED Builder interface before it may be displayed in the Iris Visualizer for analysis. This involves starting Iris and loading the data file into the tool; entering various pieces of information about the file format so that the tool can convert from the unsupported to a supported format; and then saving the converted data as a new SED segment in the SED Builder, where it may also be saved to file. The converted segment may be saved to a separate file, or may be added to other SED segments to form an aggregate SED. This is what we will do for the BZQ J2129-1538 SED: form an aggregate SED with the WISE and NED SED data in the SED Builder to analyze.
WISE.bzqj2129-1538.dat is in a non-standard format, so we are brought to the Import Setup Frame window of the SED Builder in order to specify which columns in the input ASCII table correspond to the X axis, Y axis, and Y axis error arrays. (The other, optional fields may also be filled in; refer to the “Building and Managing SEDs” section of the [Iris How-to Guide][guide] for details and instruction.)
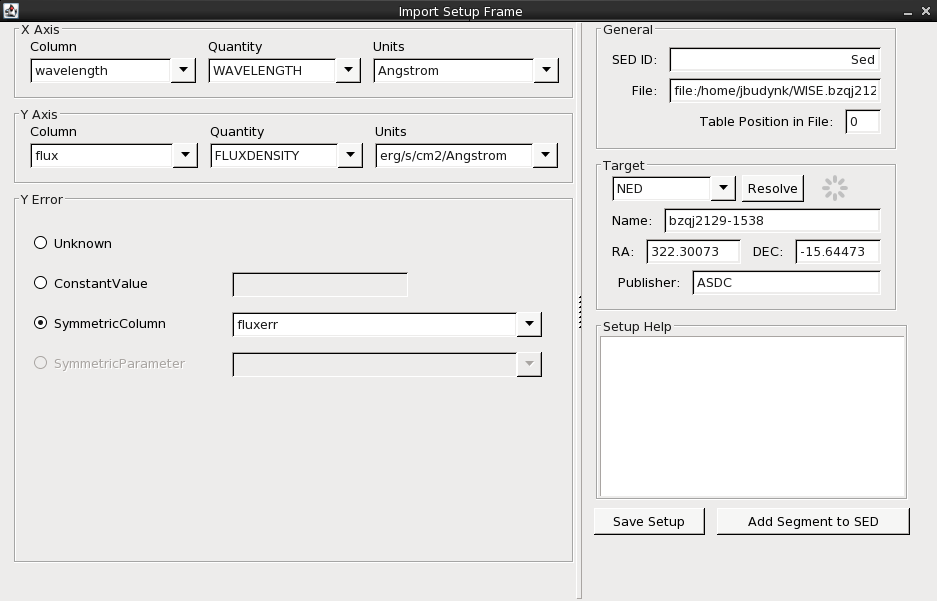
Here, we have ‘told’ Iris that the first column in our input data file corresponds to the spectral coordinate axis and contains wavelength values in Angstrom units; and likewise, that the second column contains flux density values in ergs/s/cm2/Angstrom units. Finally, we specify that the errors on the flux density values are contained in the third column of our input file (as opposed to being unknown, or of a constant value).
If we had more ASCII files to convert and add to our SED, we would save this conversion configuration to a so-called “setup” file by selecting the “Save Setup” option. This setup file would allow us to convert many data files in the same unsupported format from the command line, non-interactively; i.e., so that you do not have to re-create the same conversion setup within the GUI for each file (see Creating a Setup File for more information about configuring setup files).
Now, we click “Add Segment to SED”, and see that the WISE data is automatically co-plotted with the NED SED, and that the WISE segment (segment with 4 data points) has been added to the “Segments” list in the SED Builder window. The two segments are plotted in different colors (WISE is blue, NED is black) to help us visualize the separate segments.
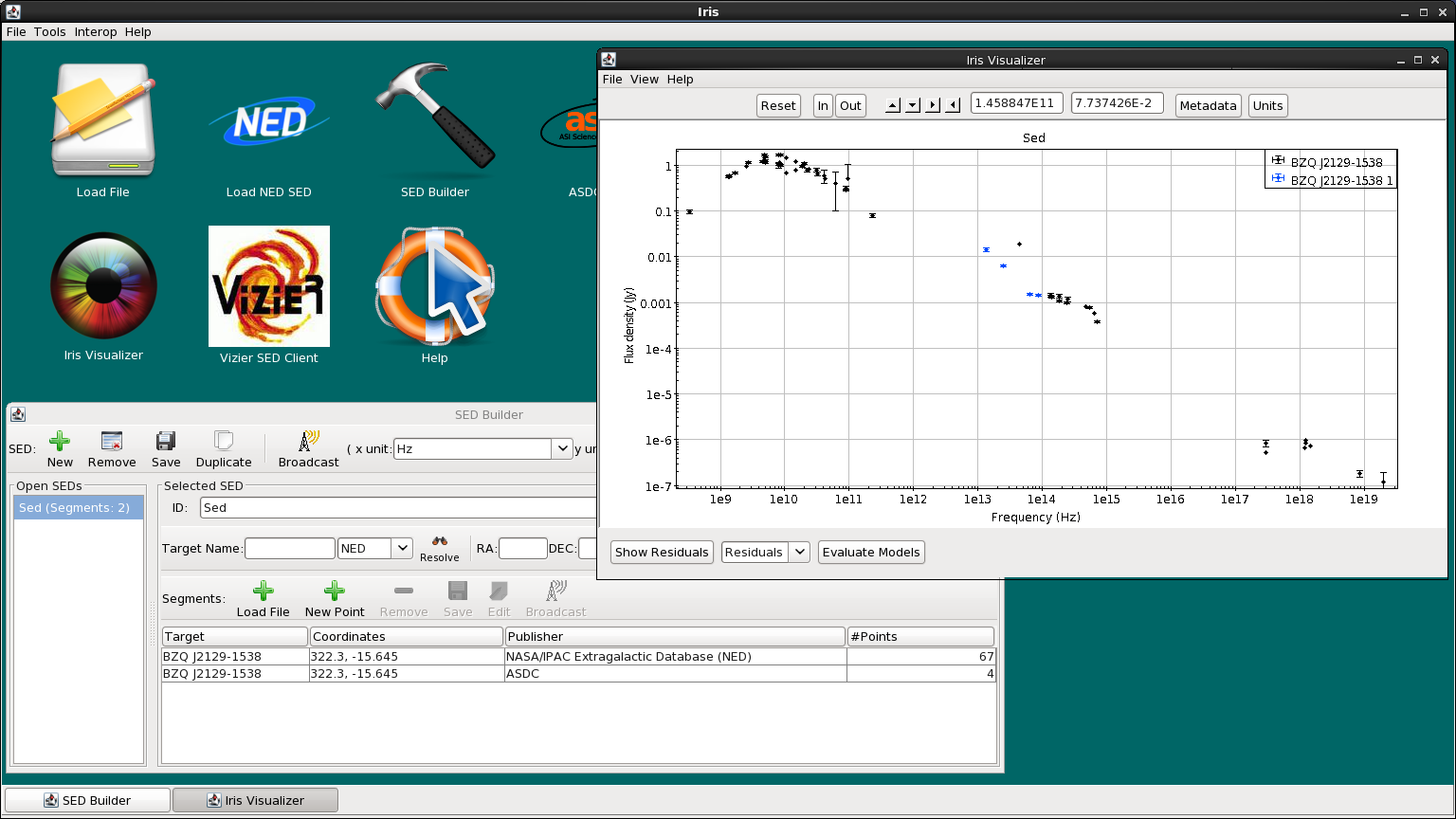
We can also save the WISE data segment in VOTable or FITS format by highlighting the segment in the SED Builder window, and clicking the “Save” button in the Segements section. We could also save the aggregate SED by highlighting the SED name in the left-column, and clicking “Save” from the top bar of the SED Builder window. You can choose to save the SED as-is or as a Single Table. The Single Table option removes all metadata, saving only the spectral coordinates, fluxes, and flux errors (a low-maintenance format for external use in other programs, but this means that the next time you load the Single Table in Iris, Iris will not be able to distinguish the two SED segments). If you wish to maintain the individual SED segments for a later session in Iris, do not check “Single Table”.
| [Back to top] |
The Iris Visualizer is an adaptation of the [Specview][specview]) spectral visualization and analysis GUI, and as a result offers several of the data display preferences of Specview. Multiple SED data segments or photometric points may be plotted simultaneously in the Iris main display, tables of metadata and data arrays may be accessed and filtered, and the attributes of several components of the display may be customized to suit your preferences.
In order to view both of the SED data segments of BZQ J2129-1538 simultaneously in the Iris display, we simply load and configure both segments in the SED Builder, as outlined above; multiple segments of an aggregate SED (those listed in the “Segments” field of the SED Builder) always display together.
Separate SEDs may also be maintained in a given Iris session, where only one is displayed at a time, by loading each new SED via the the “New” button at the top of the SED Builder window, as opposed to adding new segments in the “Segments” area (see the “Building and Managing SEDs” section of the Iris How-to Guide for details). If you wish to view two separate SEDs at the same time, you can use the “Co-plot” function under Display in the Iris visualizer tool bar.
For display purposes, let’s change the name of the SED from “Sed”, the default name, to “BZQ J2129-1538” by typing the new name into the “ID” field near the top of the SED Builder window. Renaming SEDs with meaningful titles can be helpful when analyzing numerous SEDs in an Iris session.
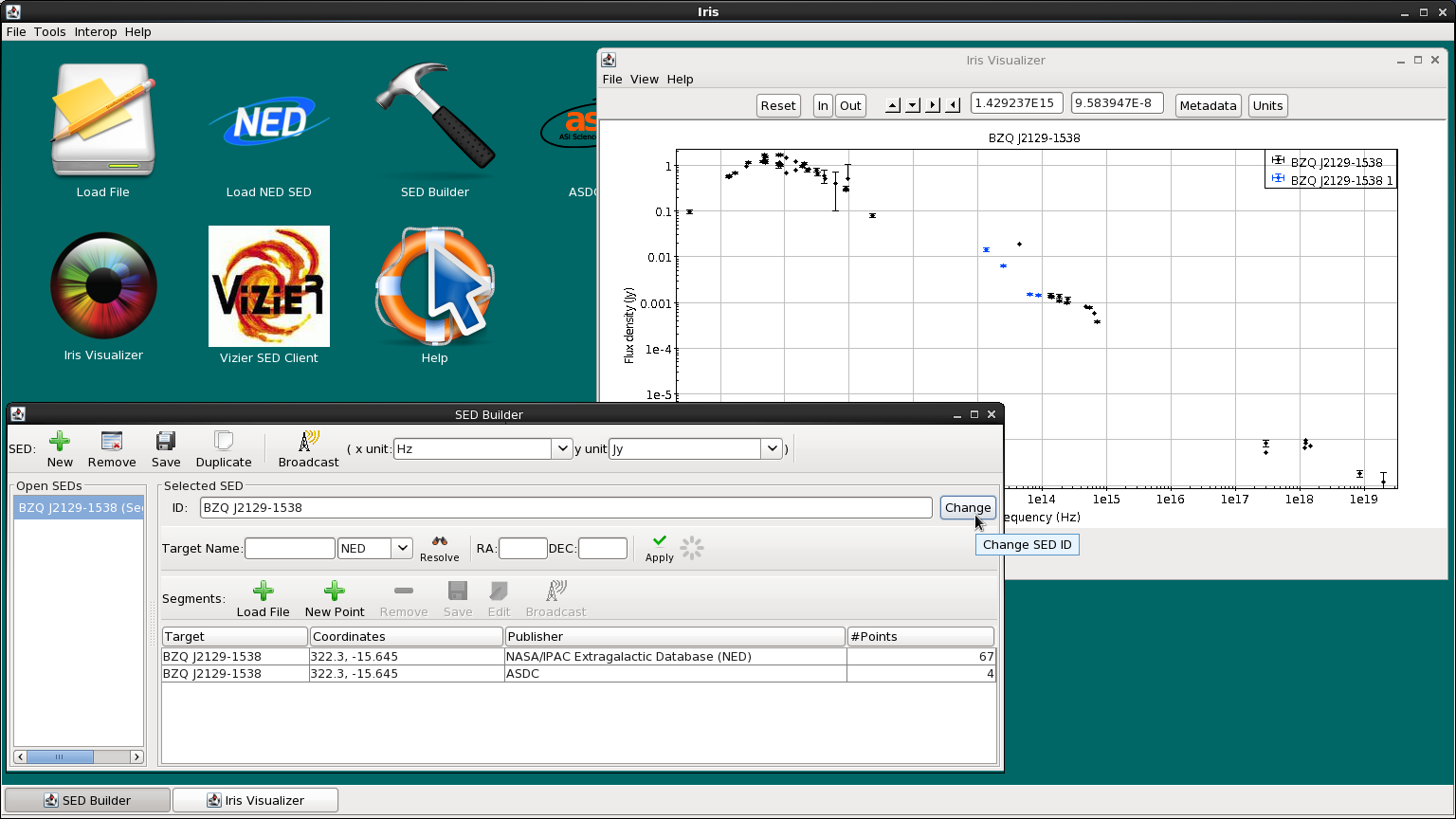
It is important to note that when multiple SED data segments are plotted together, the spectral data from each segment is not combined, coadded, or spliced in memory in any way. The raw data from the multiple input spectra is completely preserved in the resulting combination.
Finally, note that one of the loaded data segments displays in magenta-colored symbols; this indicates that the data have associated zero-value errors. Data points with zero-value errors are ignored in the model fitting in Iris (see the Iris FAQs for details).
| [Back to top] |
Clicking the “Metadata” button in the upper-right corner of the Iris display opens a window containing three separate tabs of information, the first displaying data about each SED segment, the second showing the metadata associated with each SED data point in the plot, and the third listing independent and dependent data arrays defining the plot.
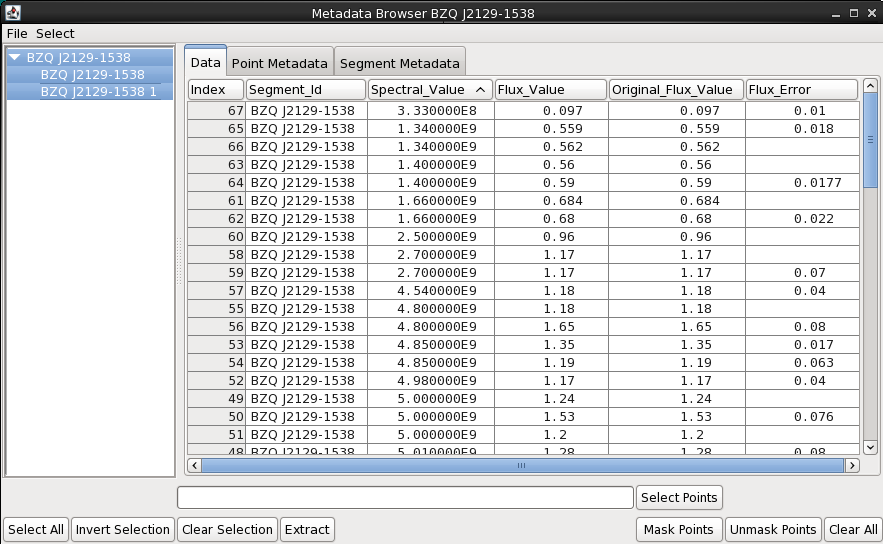
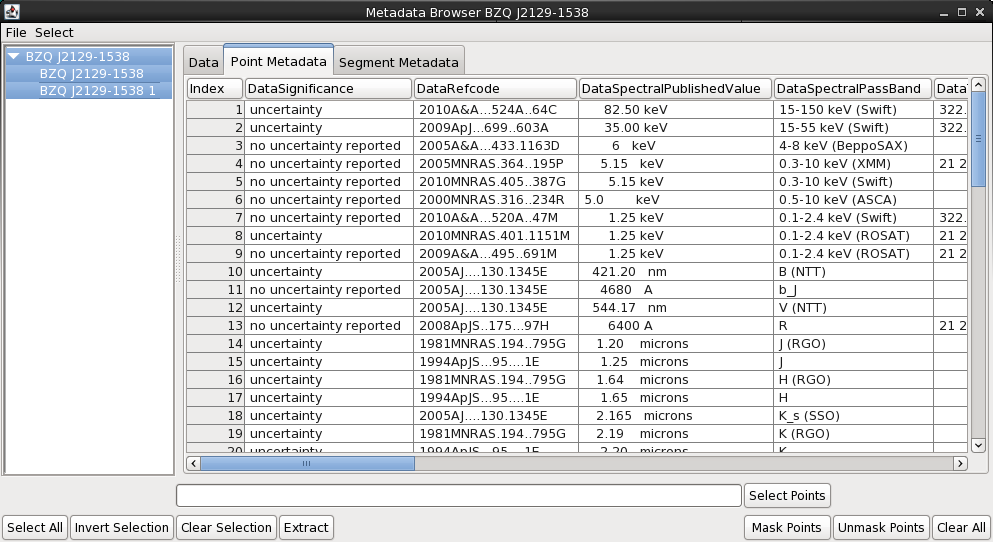
When available, the Metadata tab includes many useful pieces of information about the data points currently displayed. When a SED is imported from NED, for example, the metadata includes such things as the bibliographic reference code for each data point, the spectral range covered by instrument used to obtain data point, data point uncertainty and flux values as they are published, data point significance values, among others For the WISE data, only the data point ID and SED name is returned since our data files were loaded without associated metadata.
The Segment metadata tab displays metadata that is common to the whole SED segment. We find similar information that’s in the Metadata tab, amongst other reference information. We will not be using the segment metadata for this analysis.
The Data tab shows the X (Spectral Axis) and Y (Flux Axis)coordinate values of each SED data point in the Iris display, reflecting the values/units as they are displayed in the plot. Hovering over the spectral and flux column headers will show the units in a tooltip.
| [Back to top] |
The Metadata Browser also allows us to filter the current SED so that selected points can be masked from the Visualizer and the Fitting Tool. This can be done by selecting the rows corresponding to these points, and then clicking “Mask Points” or “Unmask Points” at the bottom of the window. In the display, the points selected in the Metadata window will disappear.
Let’s remove all photometric points without uncertainties. Here, we have masked photometric points without any reported errors using the Boolean filter in the Data tab. We type $4 > 0 into the filter (if a cell should have a numeric value but is left empty, the cell will be selected in this way). Then, click “Invert Selection”, and finally click “Mask Points.” In the resulting figure below, all points without uncertainties disappear.
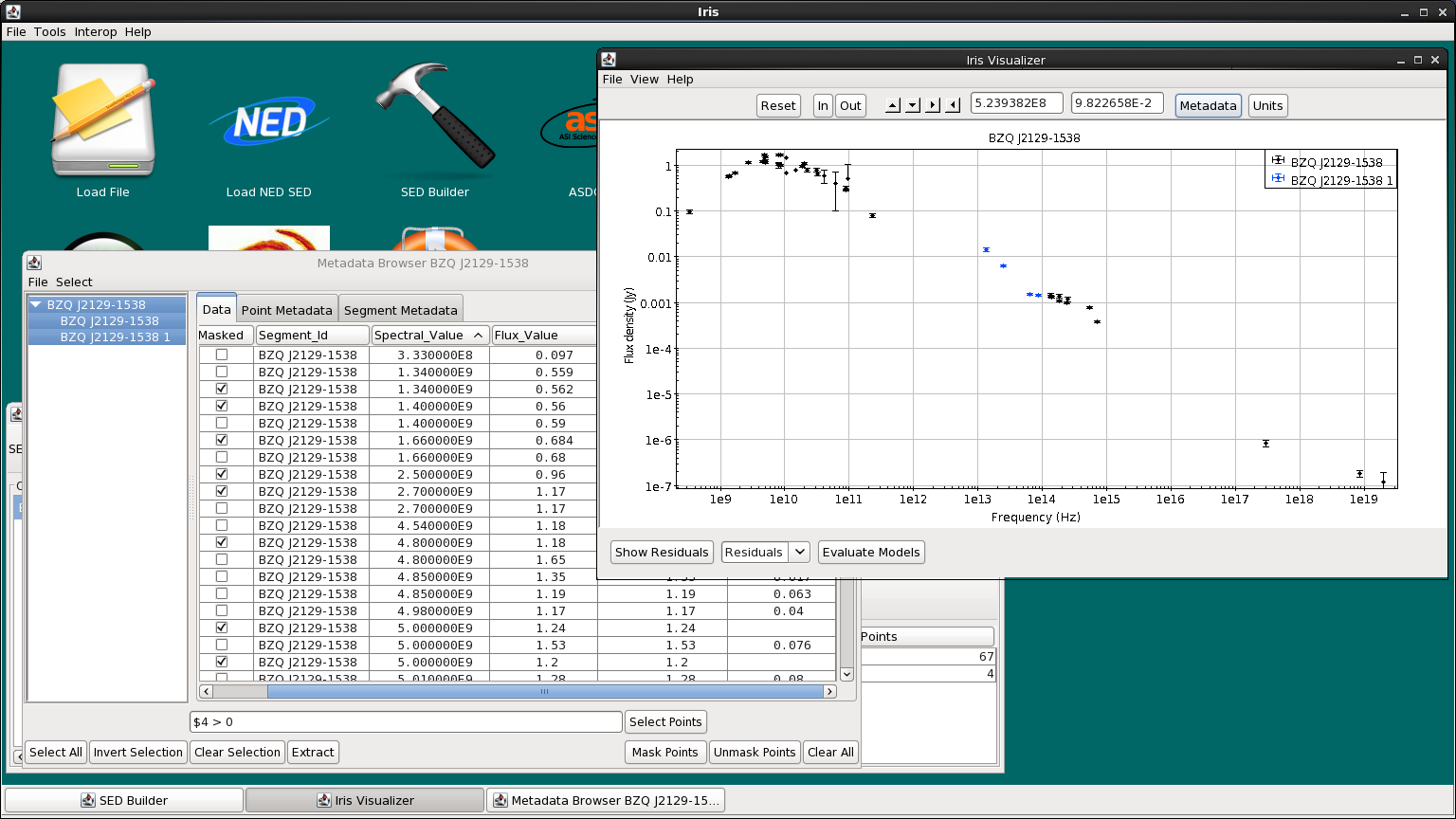
Selected data points may even be extracted into a whole new SED by clicking “Extract” after making the desired row selections in the Metadata window. This will open a new SED in the SED Builder window named “FilterSED” (you can change the ID name in the Builder) which will display in the Visualizer.
Let’s extract the filtered BZQ J2129-1538 SED from the Data tab, so that we only have the data with reported uncertainties. To do this, you can either
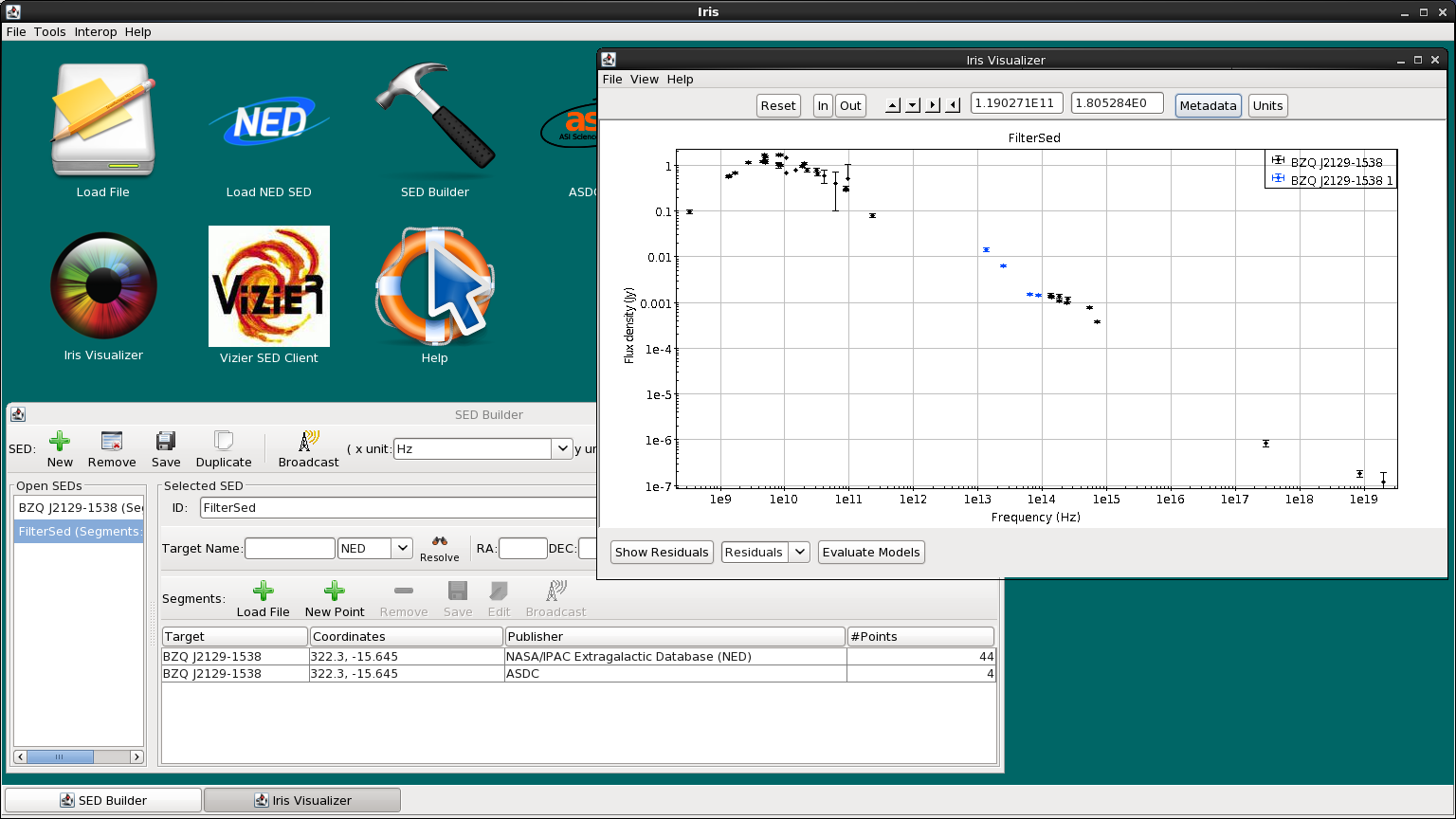
We’ll change the SED ID of the “FilterSed” to “BZQ J2129-1538 Filtered” before moving on.
| [Back to top] |
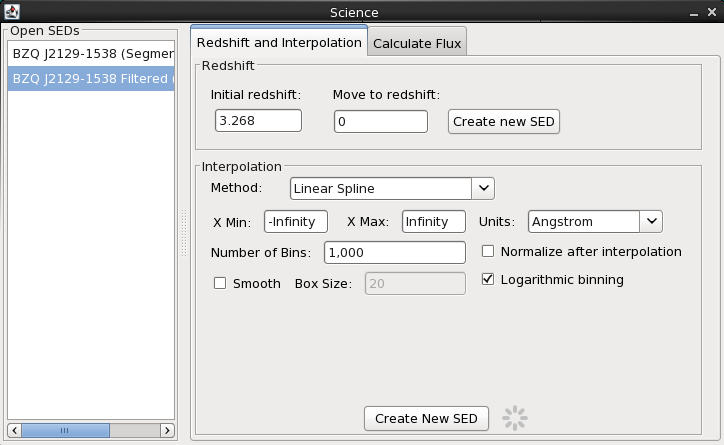
We know that BZQ J2129-1538 is at redshift z=3.268 (2001A&A…375…739D). Before analyzing our data any further, let’s shift the SED to restframe. We can easily do this in Iris. Click on the Shift, Interpolate, Integrate icon on the desktop. In the “Redshift” section of the Redshift and Interpolate tab, we type “3.268” into the “Initial redshift” field and “0” into “Move to redshift”, and finally select “Create new SED”. The blueshifted SED will automatically display in the Iris Visualizer.
Note that the indivual SED segments are combined into one, aggregate SED, and that the NED metadata is not retained.
We have two very similar (and ambiguous) names for the filtered and filtered+shifted SEDs. We can change their names from the SED Builder window. Let’s rename them to something more meaningful: “BZQ J2129-1538 FilterSed” and “BZQ J2129-1538 FilterSed (z=0)”. Note that two SEDs loaded into the SED Builder cannot chare the same ID name.
Let’s observe the change in shape from the observed to the rest-frame BZQ J2129-1538 SED. We click View –> Coplot… on the Iris Visualizer, select “BZQ J2129-1538” and “BZQ J2129-1538 FilterSed (z=0)”, and click “Co-plot”. We see that the object is brighter, and the whole spectrum shifted to higher frequencies, as expected.
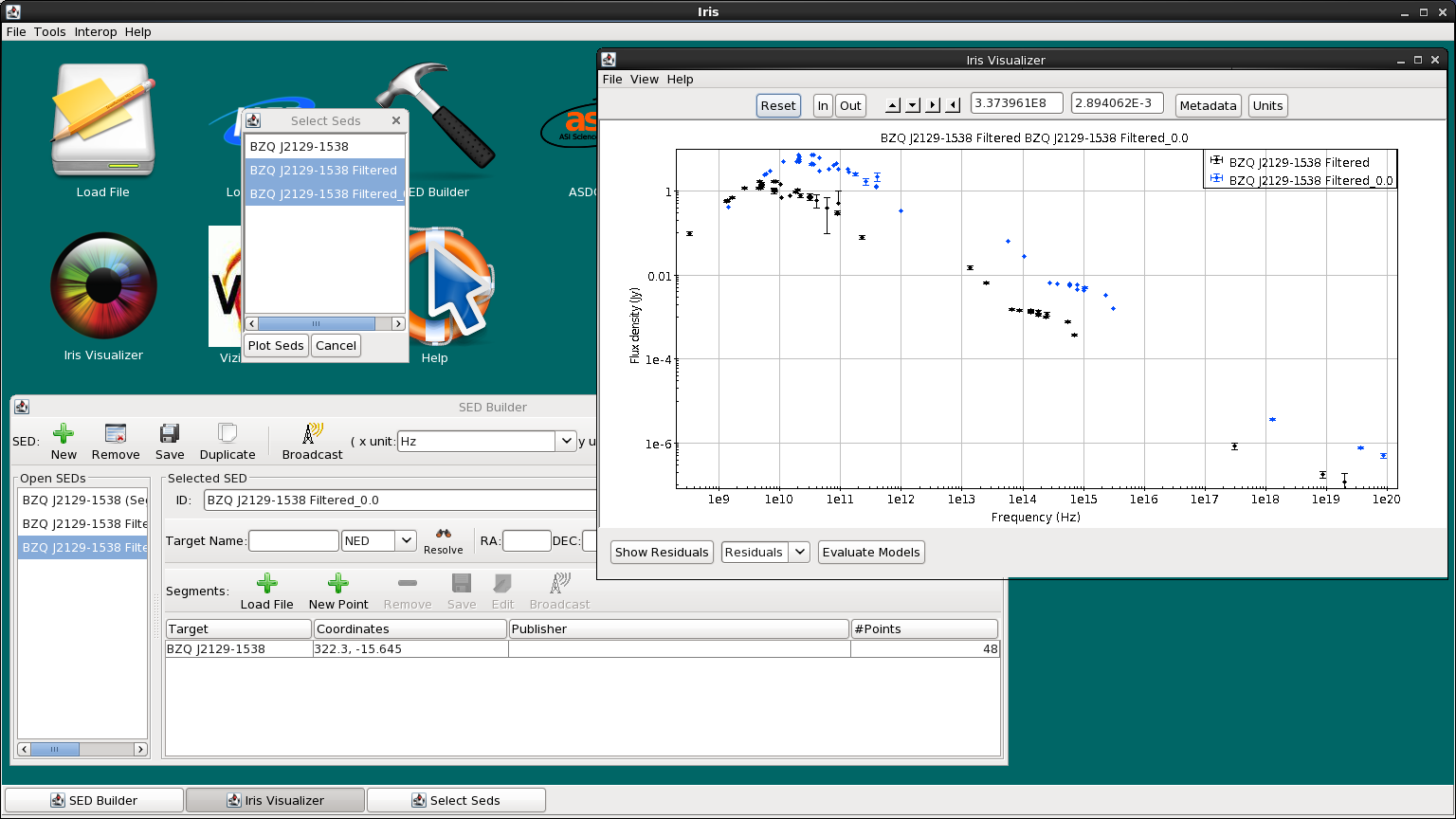
| [Back to top] |
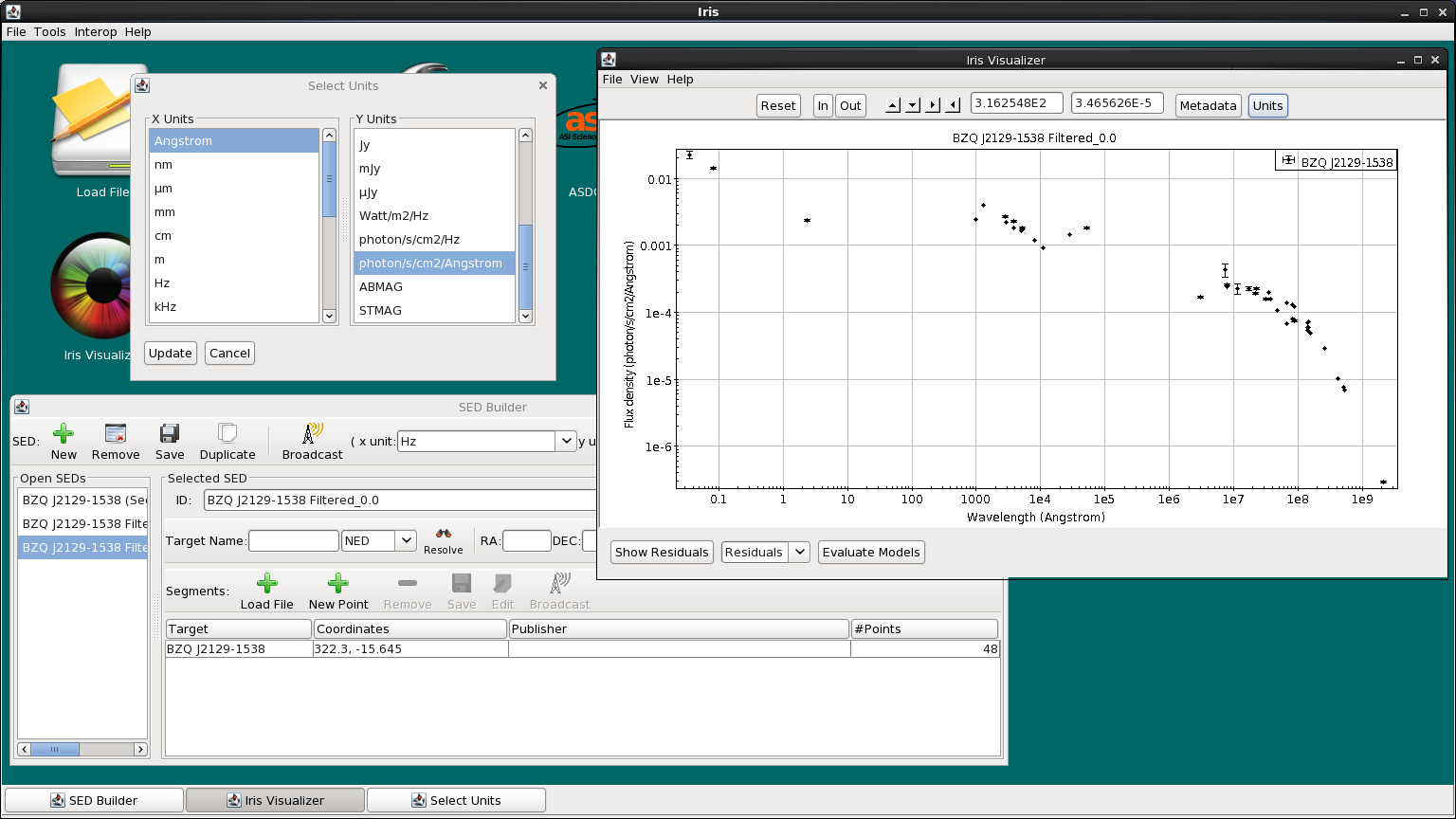
The axes units automatically displayed in the Iris Visualizer might not be the units of choice. We can change the units on the upper-right corner of the Iris Visualizer with the “Units” button. You may choose the desired X- and Y-axis units to display the SEDs in. Note that the rows in the Metadata Browser “Data” tab will update to reflect the plot units.
In our case, we want to plot in λ f(λ) vs λ for reasons that will be clear when we start to fit the data (see the next section). On clicking “Units”, we choose “Angstroms” from the left column and “photon/s/cm2/Angstrom” from the right. for the spectral axis and flux axis, respectively.
| [Back to top] |
Having loaded our desired BZQ J2129-1538 SED data and set our data display preferences, we are ready to define a model expression and fit the model to the data. The resulting best-fit values for the SED model parameters, and confidence limits on them, are physically meaningful quantities which we will use in our analysis of BZQ J2129-1538.
We initiate the fitting process by selecting the “Fitting Tool” icon on the Iris desktop.
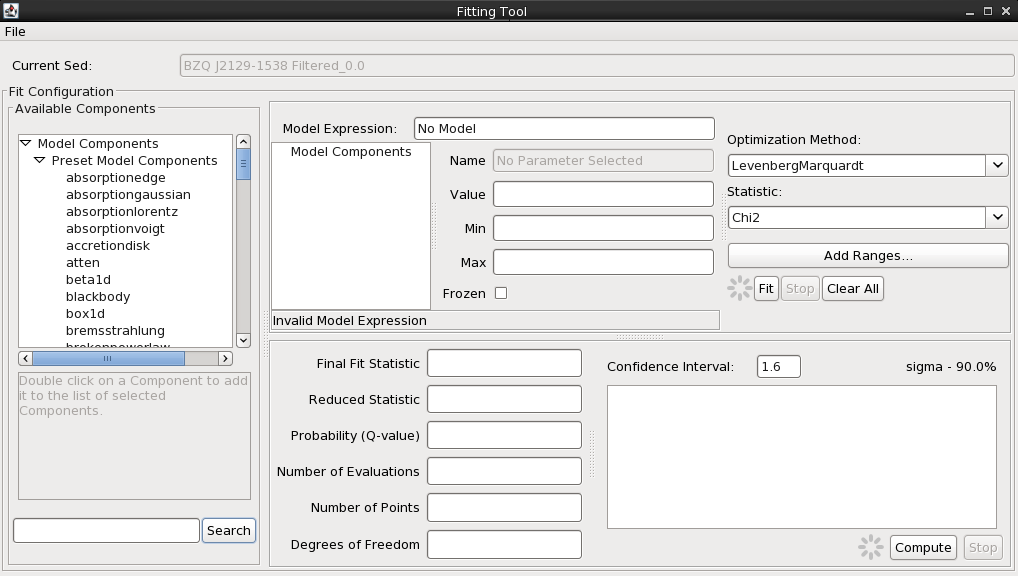
The Iris Fitting Tool allows you to define a single or multi-component model expression, set starting model parameter values and ranges, and choose from among a list of robust fit statistics and methods. It also allows you to calculate the specified percent/sigma confidence intervals on best-fit model parameters, to assess the quality of the fit (e.g., entering “1.6” for 1.6-sigma, 90% confidence).
You may edit the SED data during a fitting session. If you fit an SED, then edit the SED data afterwards (e.g., add/remove a segment, mask/unmask data), a warning will pop-up saying the the fit results do not reflect the current SED.
Before we start fitting the data, let’s talk about the physics of this SED, which will help us choose the right models. FSRQ blazar SEDs are dominated by two characteristic “bumps” in the infrared and gamma-ray regimes, as well as what’s called the “Big Blue Bump” at optical/UV wavelengths. These features are thought to be caused by synchrotron emission at low frequencies, inverse-Compton (IC) radiation at high energies, and black body radiation from the accretion disk in the center of the galaxy at optical/UV wavelengths (Dermer et al. 2009). It has been shown that the synchrotron and IC emission can be modeled by logarithmic parabolas. Therefore, we’ll need two log-parabolas and an accretion disk model for the X-ray regime to the “Components” list for fitting.
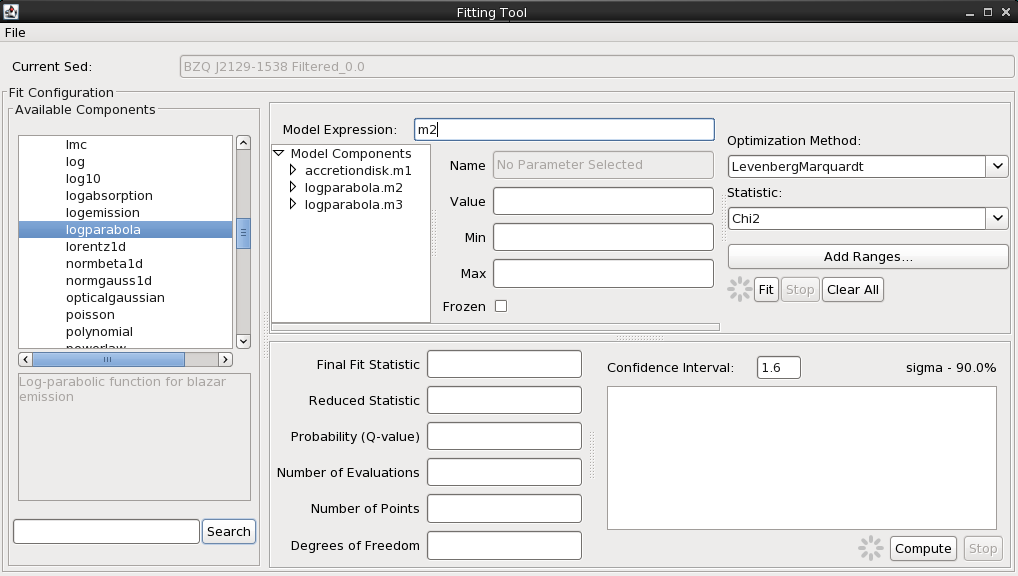
From the list of Model Components on the left-hand side of the Fitting Tool, you will find built-in Sherpa models of optical, X-Ray, and general mathematical and astrophysical models under “Preset Components”, and at the bottom of the list are any of the Custom Models you’ve imported to Iris (see the Custom Model Manager to learn how to import your own templates and Python functions into Iris). From the “Preset Components” list, we make three selections: “accretiondisk” once, and “logparabola” twice, in order to define these as the components with which to build our full model expression. The components will appear with identifiers m1, m2, and m3 in the “Model Expression” field and the smaller “Model Components” list.
Iris automatically linearly combines the model components as their added to the user’s fitting session.
The SED spans more than 10 decades in frequency with large regions of sparse data. Therefore, we will fit the components one-at-a-time, freezing the parameters of the other components as we fit one component.
We will start by fitting the synchrotron emission peak, modeled by the log-parabola, m2. Remove m1 and m3 from the Model Expression field so that the field only shows m2.
| [Back to top] |
Next, we set some initial model parameter values for the fit. To view and edit the model parameters for the added components, you can toggle the model name, select the parameter to edit, and modify the parameter value and its minimum/maximum ranges in the respective fields. For more details, visit Setting Model Parameters in Modeling and Fitting SED Data in Iris.
Note: The internal units for fitting in Iris have been in photons/s/cm^2^/Angstrom vs Angstroms because of a previous [Specview][specview] dependency, so all of the values entered into the parameter fields must be in or photons/cm^2^/Angstrom or Angstroms. This is why we switched the plot axes to these units; by hovering over the plot with the cursor, one can better estimate what initial model parameters to use. Note that we plan to let users choose in which units they wish to fit in the future.
Let’s edit the initial values for m2. Toggle model component m2. There are 4 parameters for the logparabola model:
f(x) = A * (x/x_ref)^[-gamma - beta*log10(x/x_ref)]
The log parabola for radio synchrotron emission peaks at IR wavelengths. Therefore, we’ll edit the refer position for m2 to 500,000 Angstroms, and leave the parameter fixed.
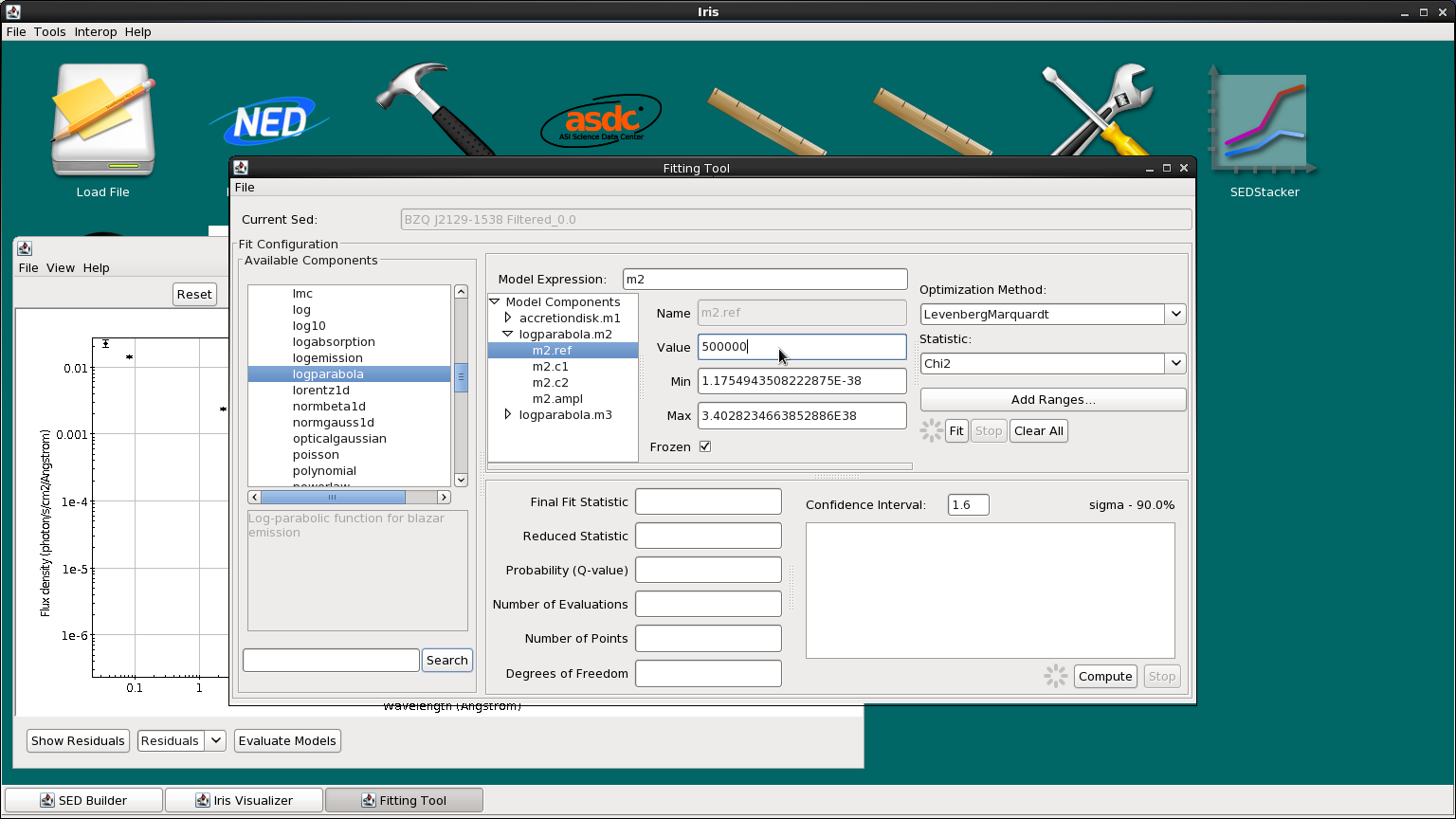
For our analysis, we choose to allow all model parameters to vary in the fit except the reference position of the log-parabolas and the accretion disk. If you wished to fix a parameter, you would uncheck the “Fit” box associated with that parameter.
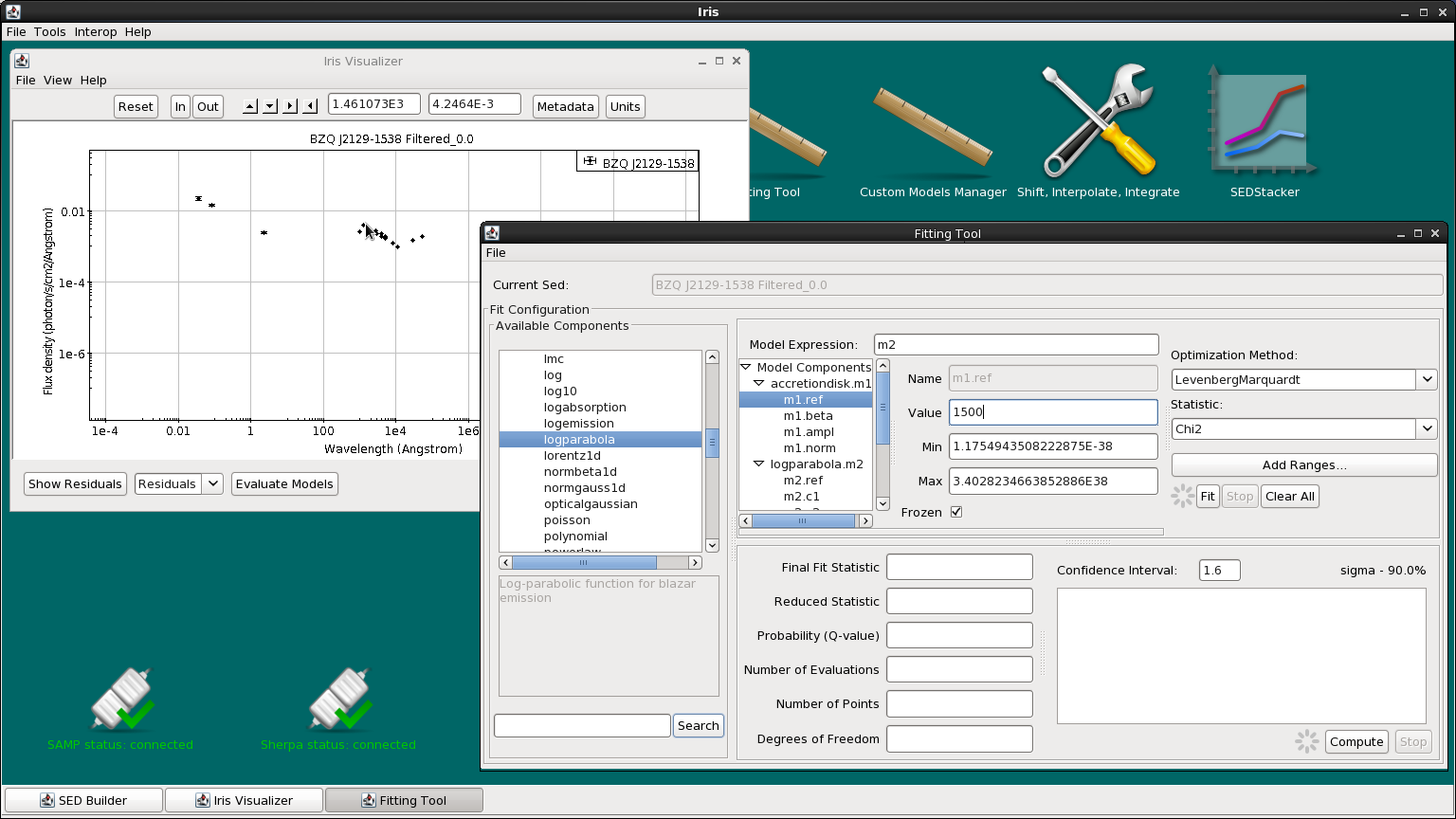
We make a guess at the peak positions of the log-parabolas and accretion disk emission (the parameter “refer”) by hovering the cursor over the points of interest in the Iris Visualizer and recording the X values (in Angstroms) in the refer Value fields. If the data points are off the sides of the plot area, click “Refresh” to re-center the plot.
Toggle “accretiondisk.c1”, select refer and enter 1500 as the initial accretion disk value. Then toggle “logparabola.c3”, again select refer, and enter 1e-3.
| [Back to top] |
By default, Iris will use the entire spectral range for fitting the models. As we’ve decided to fit the blazar components one-by-one initially, we will reset the fitting range for each model.
We’re fitting the synchrotron emission logparabola, m2, first. Open fit Fitting Ranges frame by clicking “Add Ranges…” on the right-most side of the Fitting Tool. This opens up a list of currently defined fitting ranges for the selected SED.
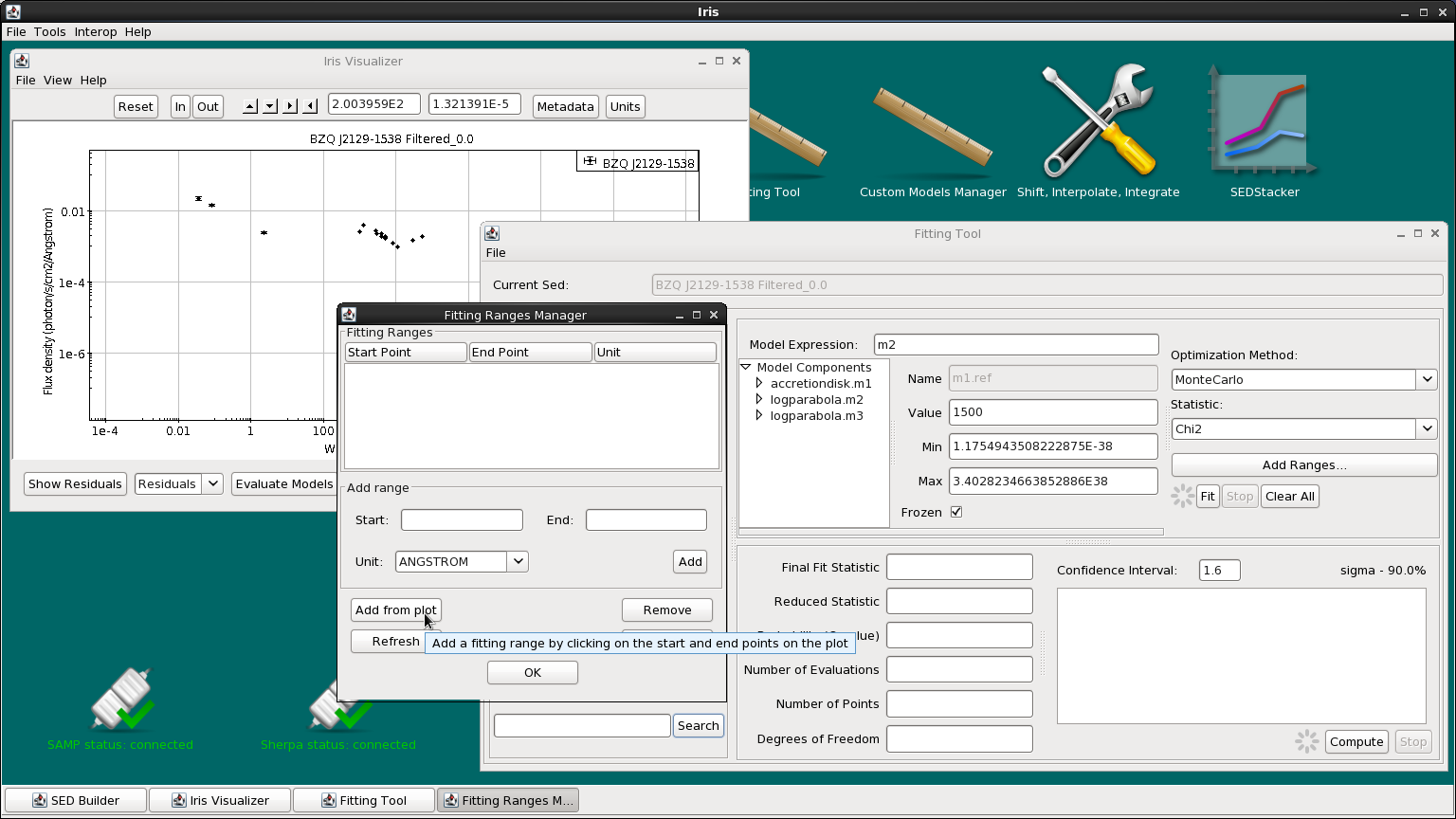
We could add specific start and end points for the range by using the “Start” and “End” fields in the frame. Or, we can click “Add From Plot”, then click on the start and end points on the plot itself. This will set a new fitting range. The start and end points will be displayed in the Fitting Ranges list.
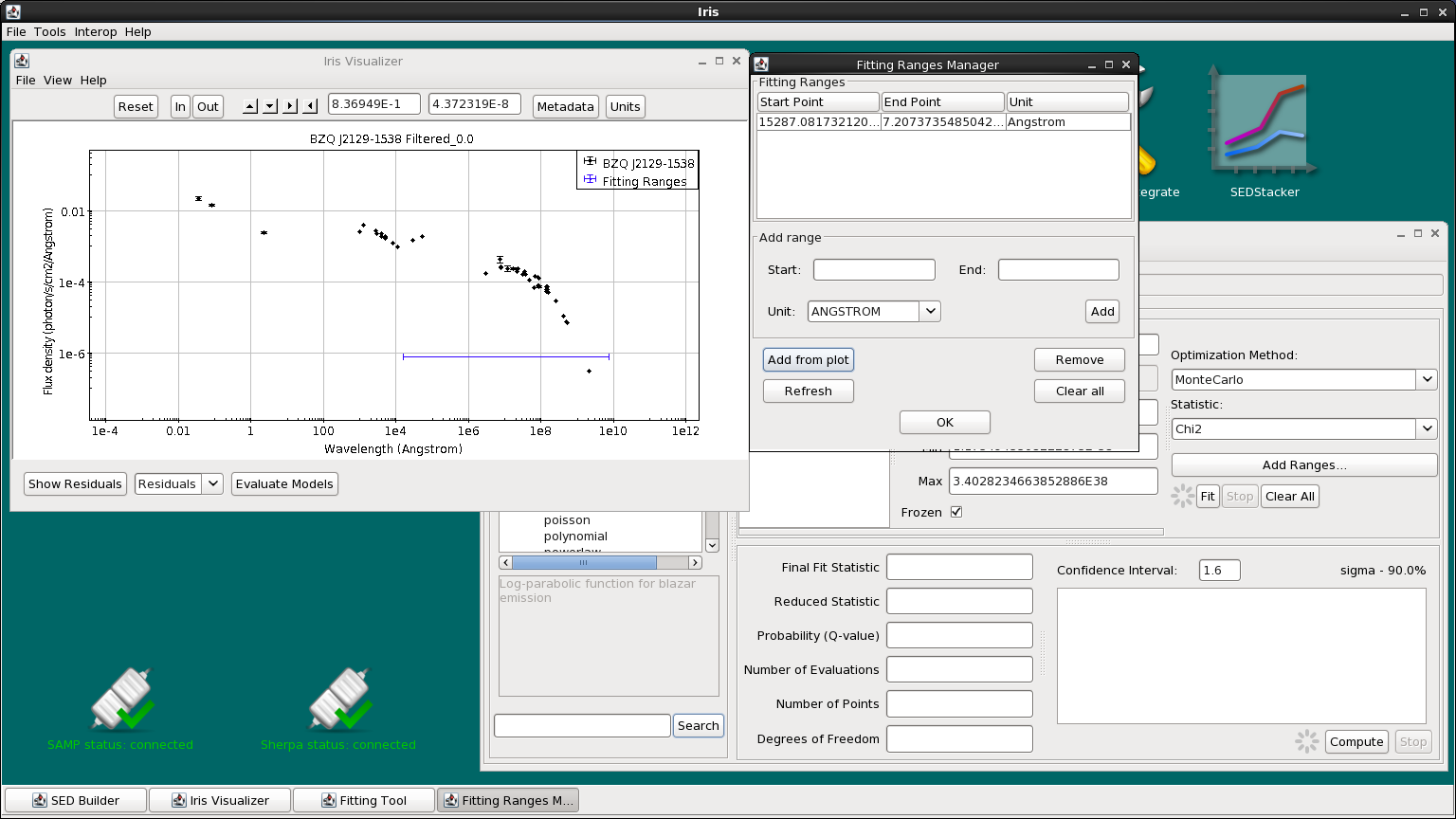
Note that multiple fitting ranges can be set at a time (useful for fitting spectral lines). Iris will only fit points that fall inside these ranges.
| [Back to top] |
Our final step in the preparation for fitting involves choosing a fit statistic and optimization method appropriate for our analysis. These options are shown on the right-most side of the Fitting Tool as drop-down menus.
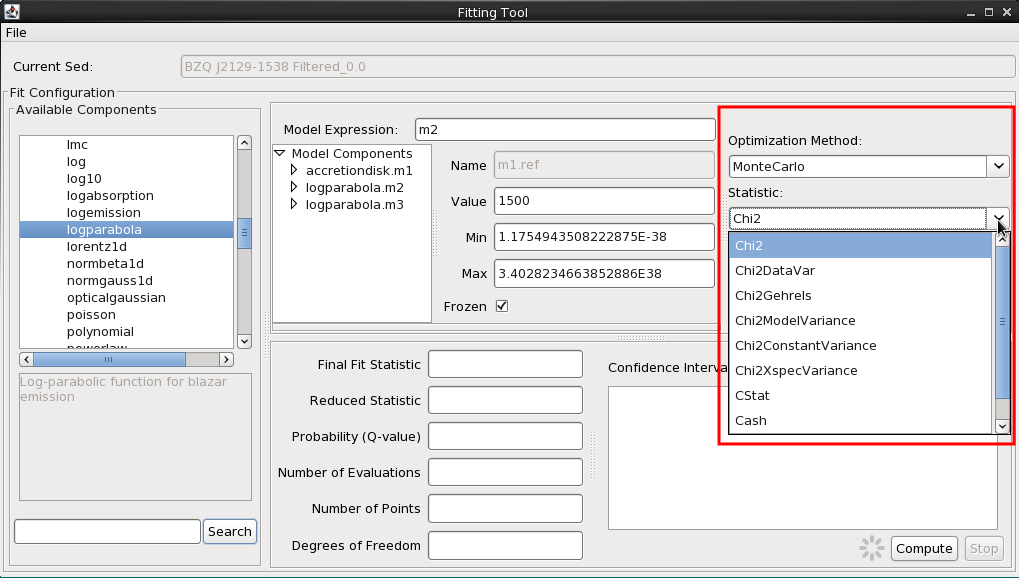
We see that the fit can be done with a least-squares statistic, or chi-squared (with various methods for estimating the variances used by chi-squared), or with either of two maximum likelihood statistics that are useful when the data have low numbers of counts.
Choose the chi-squared statistic (Chi2) and Monte Carlo (MonteCarlo) optimization.
| [Back to top] |
We are now ready to fit the data using our model expression, initial model parameters values, and chosen fit statistic and method. Clicking the “Fit” button beneath the “Add Ranges…” button initiates the fitting process.
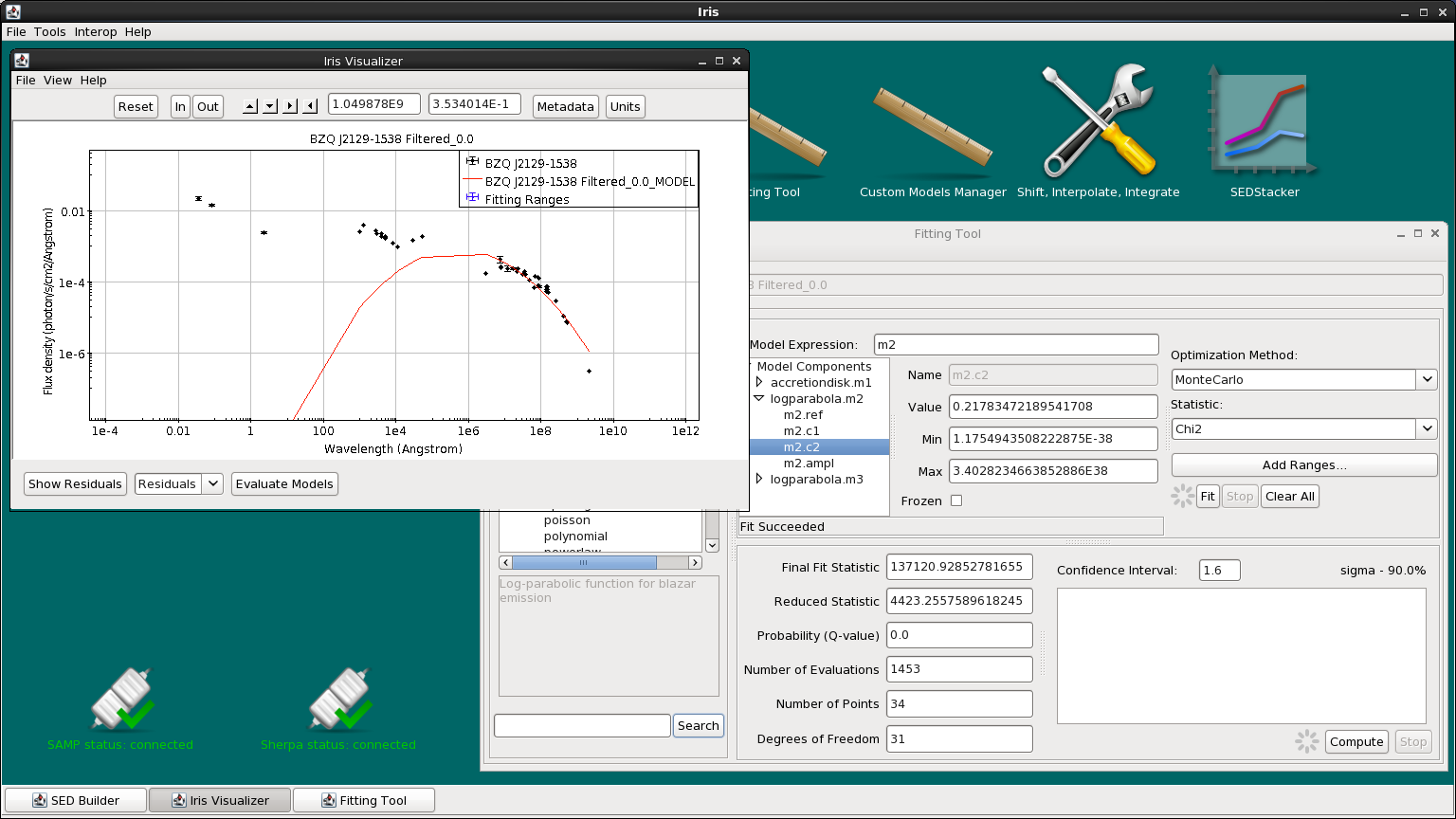
When the fit completes, we see the fitted model overlaid on the SED data in the Iris main display and the following fit statistics returned: the final fit statistic value, the number of data points used in the fit, the number of degrees of freedom in the fit, the null hypothesis probability value of the fit, and the reduced statistic.
You can also view the fit residuals from the Visualizer by clicking “Show Residuals” at the bottom. You can switch between showing the residuals in linear space (Residuals) and in dex (Ratios).
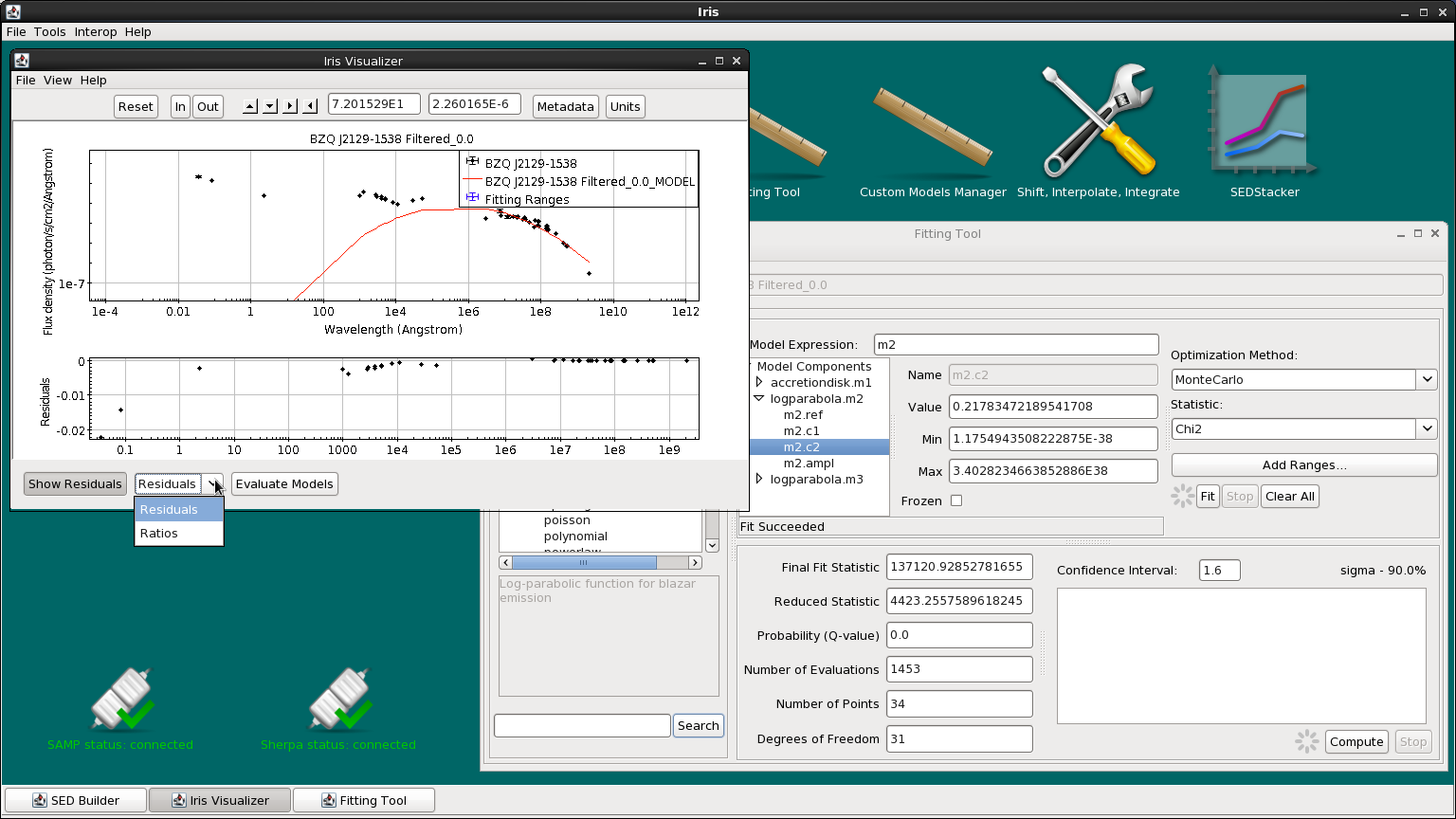
We still have two more components to add to our model. Now, let’s add the accretion disk model, m1 to the Model Expression field. The model should now read m2 + m1.
First, we freeze m2 before refitting the new model expression. Right-click the log-parabola model in the Model Components list and select “Freeze All Parameters”.
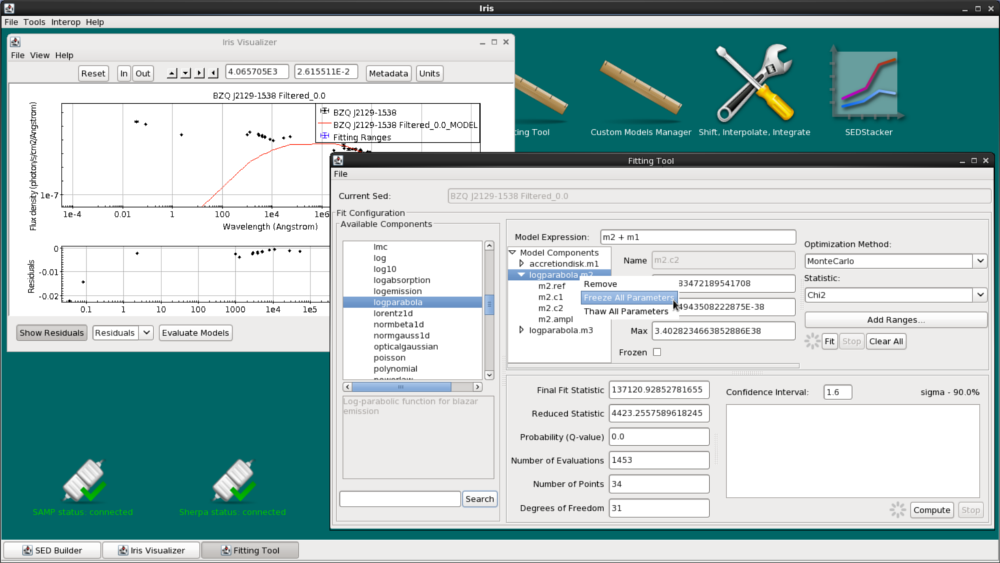
Open the Fitting Ranges window (click on “Add Ranges…”), “Clear All” the fitting ranges, and then set the fitting range to include only the UV-to-near-IR data.
Let’s again use the Monte-Carlo method with chi-squared statistics, and click “Fit”. This time, the data takes a little longer to fit; this is because our model is more complex.
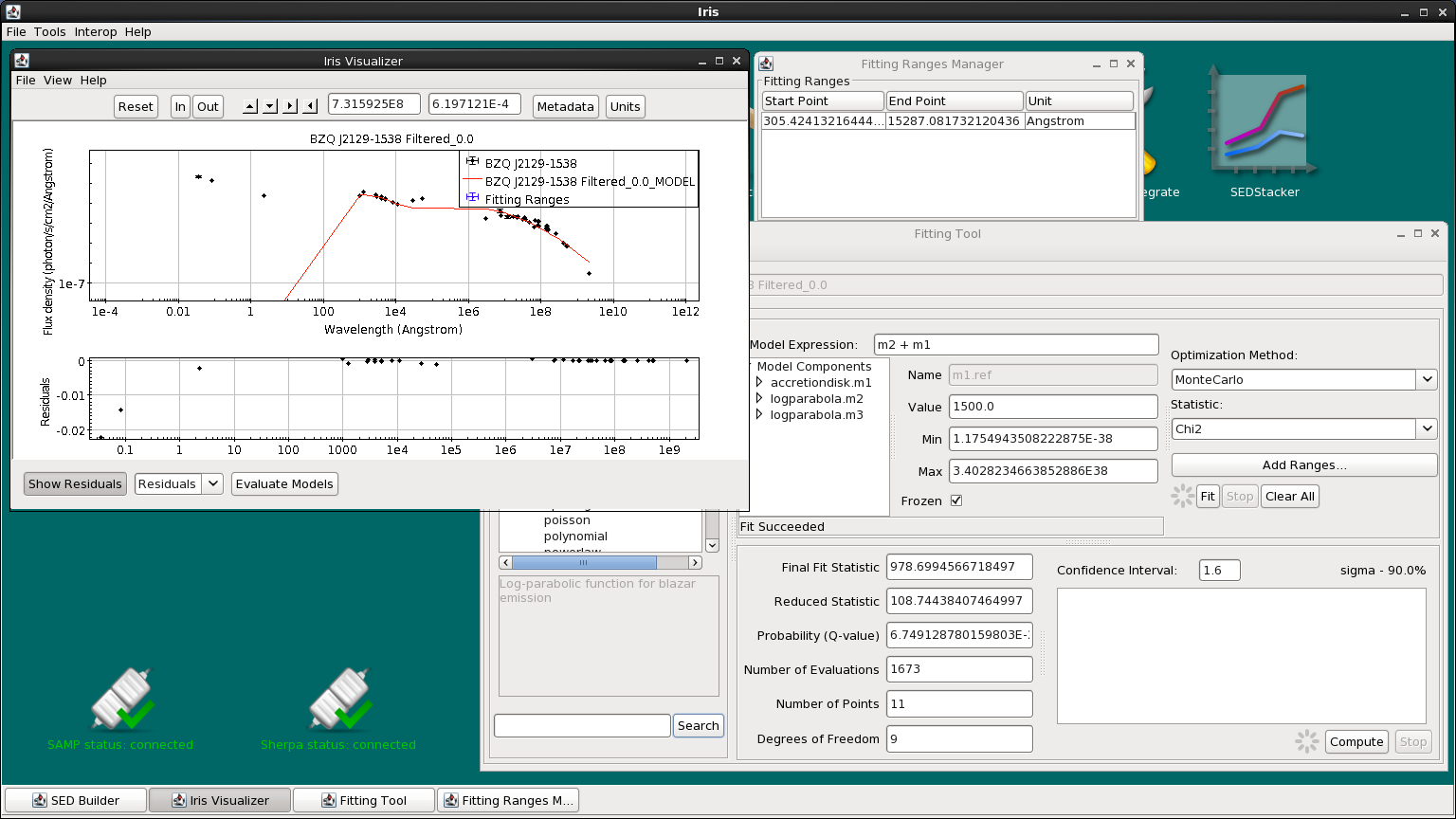
Now we’ve got the optical/UV range fit. Let’s add our last component, the inverse-Compton log-parabola m3, to the model expression. Again, we freeze the accretion disk parameters, reset the fitting range to only include the high-energy data, and choose Monte-Carlo + chi-squared to fit the rest of the data.
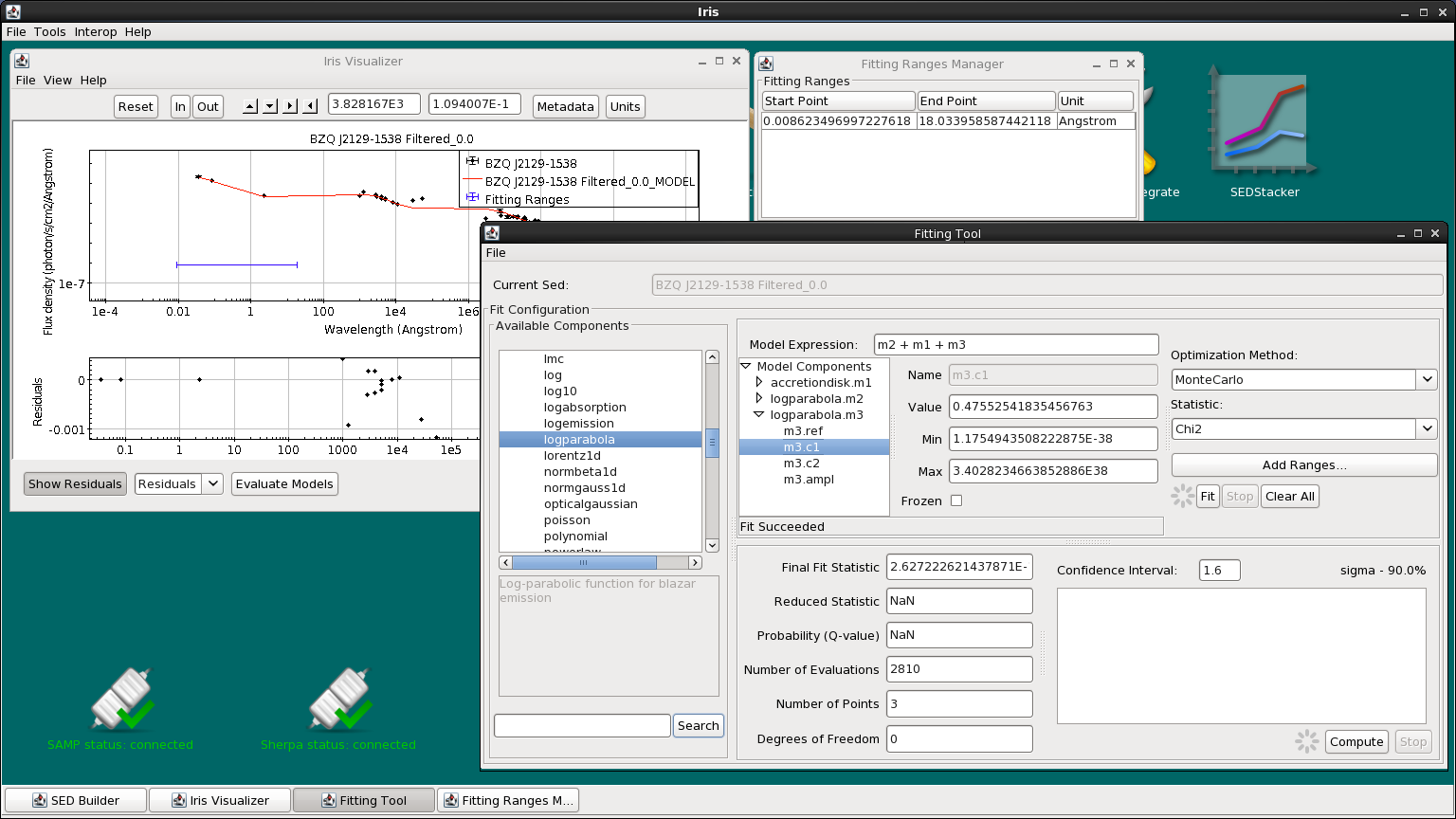
Now that we have decent parameter values, we can unfreeze all the parameters (except for the logparabola’s refer positions and the accretion disk’s normal parameter which must remain fixed), switch the statistic to “NelderMeadSimplex” (since Monte Carlo is time consuming with so many free parameters), and fit again.
We can calculate the confidence limits on the thawed parameters. Switching over to the Confidence tab in the window displaying fit statistics, we enter “1.6” in the “Confidence Interval” field and click “Compute” to calculate and display the 90% confidence limits on the best-fit model parameter values.
NOTE: This calculation may take awhile (1-2 minutes) because of the number of free parameters.
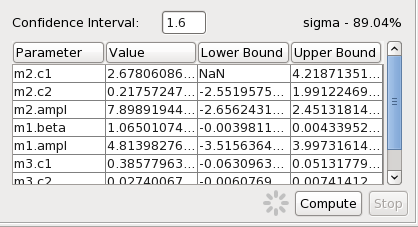
Not completely satisfied with this initial fit, we adjust the model parameter values to better match the data, experiment with different chi-squared fit statistics, and then re-fit. We continue on in this fashion, iterating through the fit - freezing and thawing model parameters; adding or deleting models from the model expression; changing parameter values or ranges; experimenting with different fitting ranges - until we find a satisfactory model that best describes our BZQ J2129-1538 SED. Finally, we opt to write our custom model expression and best-fit parameters to file via the “Save” option in the Iris Fit window, in order to resurrect this particular fit in a future Iris analysis session.
| [Back to top] |
During a SED analysis session in Iris, it is possible to write to file the SED data arrays, as well as the customized fitting session. These output files may then be imported back into Iris for future analysis. See Saving SED Data for more details.
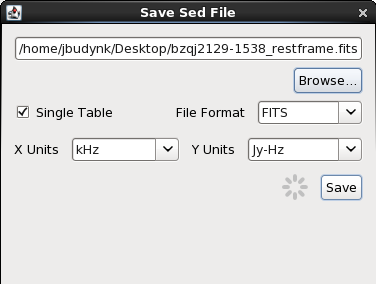
The SED data open in an Iris session may be written to one or multiple FITS (.fits), VOTable (.vot), or ASCII format files (you can save each segment to a separate file, or save the multi-segment SED to one file). For example, to save our BZQ J2129-1538 SED to a FITS format file (which excludes model data values) we would select the “Save” option at the top of the Iris SED Builder window, to create file bzqj2129-1538_restframe.fits. We could then access our saved SED data in a future session of Iris simply by selecting the “Load File” icon on the Iris desktop, and browsing our disk for file bzqj2129-1538_restframe.fits.
We have the option to save the SED as-is – meaning with all available metadata – or as a Single Table. The Single Table option removes all metadata, saving only the spectral coordinates, fluxes, and flux errors (a low-maintenance format for external use in other programs, but the next time you load the Single Table in Iris, Iris will not be able to distinguish multiple SED segments). If you wish to maintain the individual SED segments for a later session in Iris, do not check “Single Table”. For our data, this is a non-issue, as our rest-frame SED of BZQ J2129-1538 has no metadata (remember that shifted SEDs lose all metadata); it does not matter if we check “Single Table”.
| [Back to top] |
The current state of the fitting session can be saved to file at any time. There are two output formats: (1) “JSON”, which can be re-read into Iris to restore the fitting session or to evaluate/fit on other SEDs, and (2) “Text”, which saves all the models, parameters, fit statistics, etc. to a human-readable ASCII file.
We save the model to JSON by selecting “File –> Save Json…” from the fitting tool.
Now let’s save the model to a basic text format to show our colleagues the fit results. Choose “File –> Save Text…”. Here is an example of the output from the BZQ J2129-1538 fit:
Iris Fitting Tool - Fit Summary
SED ID: BZQ J2129-1538 Filtered_0.0 (Segments: 1)
Model Expression: m2 + m1 + m3
Components:
accretiondisk.m1
m1.ref = 1.50000E+03 Frozen
m1.beta = 1.06501E+00
m1.ampl = 4.81398E-04
m1.norm = 2.00000E+04 Frozen
logparabola.m2
m2.ref = 5.00000E+05 Frozen
m2.c1 = 2.67806E-11
m2.c2 = 2.17572E-01
m2.ampl = 7.89892E-04
logparabola.m3
m3.ref = 1.00000E-03 Frozen
m3.c1 = 3.85780E-01
m3.c2 = 2.74007E-02
m3.ampl = 9.78416E-02
Fit Results:
Final Fit Statistic = 1.33888E+05
Reduced Statistic = 3.34720E+03
Probability (Q-value) = 0.00000E+00
Degrees of Freedom = 40
Data Points = 48
Function Evaluations = 1738
Optimizer = NelderMeadSimplex
Statistic (Cost function) = Chi2
Confidence Limits at 1.60 sigma (89.04%):
m2.c1: ( NAN, 4.21871E-05)
m2.c2: (-2.55196E-04, 1.99122E-04)
m2.ampl: (-2.65624E-06, 2.45132E-06)
m1.beta: (-3.98120E-03, 4.33953E-03)
m1.ampl: (-3.51564E-06, 3.99732E-06)
m3.c1: (-6.30963E-02, 5.13178E-02)
m3.c2: (-6.07694E-03, 7.41412E-03)
m3.ampl: (-2.07911E-02, 2.41469E-02)
User Models:
And that’s the basics of using Iris to build, view, edit, and fit an SED.
Please view the other threads for more details and use cases. If you have any trouble, have comments or suggestions, please don’t hesitate to contact us through the CXC HelpDesk.
| [Back to top] |
| Date | Change |
|---|---|
| 08 Aug 2011 | updated for Iris Beta 2.5 |
| 26 Sep 2011 | updated for Iris 1.0 |
| 11 Jul 2012 | updated for Iris 1.1 |
| 02 Jan 2013 | updated for Iris 1.2 |
| 21 Jun 2013 | updated for Iris 2.0 |
| 24 Jun 2013 | fixed editted “ascii_setup.ini” typo |
| 11 Jul 2013 | fixed contents links. |
| 05 Aug 2013 | Updated analysis example for Iris 2.0. |
| 02 Dec 2013 | Updated for Iris 2.0.1 |
| 07 May 2015 | Updated for Iris 2.1 beta. |
| 22 Feb 2017 | Updated for Iris 3.0. |
| [Back to top] |